Buenas tardes,
Aquí estoy luego de un largo período de tiempo en el que no le daba feed al blog. Varios fueron los motivos. Básicamente nuevas responsabilidades profesionales que requirieron de mi dedicación absoluta y cierto agotamiento que me llevó a este marcado paréntesis.
Quiero agradecerles a todos y cada uno de Uds. los distintos mensajes, correos y consultas recibidos. Me han hecho ver que el blog sin dudas cumple con su objetivo, que no es otro que el de poder retroalimentar con mis pequeños aportes esta inmensa red profesional de colegas con ganas de aprender y a la vez aportar sus conocimientos.
Sin más introducciones vamos a este nuevo posteo.
Hoy
les traigo un tema con el que seguramente han tenido que lidiar en más de una
oportunidad...
Se
trata de aquel que tiene que ver con la necesidad de generar un ID único que identifique los registros de
una tabla “cuore” del sistema.
Cuando
hablamos de tabla “cuore” hablamos de aquellas tablas bases del sistema que
suelen ser referenciadas por varias tablas secundarias precisamente a partir de
su ID.
Pensemos
por ejemplo en un ID de una tabla de “Operaciones” donde registramos todas las
transacciones de los clientes de un banco. Dicho Id tendrá luego que
sincronizarse como parte del registro de las operaciones en otras tablas
secundarias.
El
desafío, y de ahí el origen de este post, es que, en la horas “pico”, donde la
tabla de “Operaciones” está siendo objeto de numerosas inserciones casi paralelas,
la generación del nuevo ID.
1) No produzca contención por demoras en el
proceso de inserción.
2) No genere intentos de inserción de
registros duplicados cuando dicho Id es insertado en tablas secundarias.
Es así
que les propongo transitar distintos métodos con sus pros y sus contras.
METODO 1. Generación de ID
Autoincremental a partir campo Indentity
Es el método tal vez
más utilizado.
Se define una tabla con
un campo Id que tendrá un valor único al ser definido como “Identity”. Dicho
campo incrementará su valor cada vez que
la tabla es insertada.
Luego, se recupera el
valor del ID insertado por medio de la función del sistema @@IDENTITY para su eventual sincronización en tablas
secundarias.
Ejemplo:
-- 1) Creación Tabla con "Id" tipo
identity --
Create Table Operaciones
(Id int NOT NULL IDENTITY(1, 1),
Detalle varchar(50) NULL)
-- 2)
Inserción de registro en Tabla ---
Insert Into Operaciones(
Detalle)
Values ( 'Articulo 234-e venta')
-- 3)
Obtención del Id para insertar en tablas secundarias ---
Declare @Id
integer
Select @Id
= @@identity
Ventajas
La facilidad de
implementación. Tal vez acorde a ello sea la solución más implementada.
Desventajas
Eventualmente puede causar
varios problemas veamos:
Ø “Problema de Inserción en la Última Página“
He podido observar a
lo largo de mi trayectoria como DBA un problema
que se repite una y otra vez en tablas “cuore” definidas bajo esta
modalidad en sistemas con una alta carga transaccional.
Este problema deviene
de la definición de la Primary Key sobre el campo “Id” identiy.
Pero por qué habría
de representar un problema la definición de la Pk sobre dicho campo?
Porque normalmente
para la definición de dicho PK se utiliza la interface del Sql Server la cual
termina generando un Indice Clustered sobre el campo Id por default.
Ejemplo seteo de Pk
por Consola:
Código que se
implementa en la práctica:
Alter Table [dbo].[Operaciones]
Add Constraint [PK_Operaciones] Primary Key Clustered
([Id] ASC)
GO
Es así pues, que nuestra tabla “Operaciones”, pasa
a tener un campo ID con las siguientes características (yo la llamo la “tripleta
del problema”):
-
Identity
-
Primary Key
-
Clustered
Contando con estas
tres características la tabla es firme candidata a sufrir lo que se conoce como
“Problema de Inserción en la Ultima Página”
Este problema afecta
a tablas que están siendo intensamente insertadas con hilos de procesamiento
paralelos debido a que todas las inserciones son dirigidas hacia el mismo
sector de la tabla produciéndose entonces una fuerte contención que se traduce
en notorias demoras en los procesos de inserción de registros en horarios pico.
La solución sería
definir la Pk como nonclustered si las reglas de negocio así lo permiten.
Ø Eventual duplicación de IDs
Otro inconveniente en
este tipo de esquemas tiene que ver con aquellos escenarios en los que el nivel
de inserciones es muy significativo y el ID recuperado por medio de la función
@@identity, y almacenado en la variable
@Id, se duplica al no llegar a
refrescarse la variable @Id por la extrema concurrencia del hilos de inserción,
casi paralelos en horas pico.
Como consecuencia de
esta eventual incidencia inmediatamente nos encontraremos con intentos de
inserción fallidos por intento de violación de PK de tablas secundarias.
Hay una solución para
evitar duplicaciones?
Si, el incluir la
inserción en la tabla y la obtención de @ID en una transacción.
Veamos:
Begin Transaction
--- Inserción de registro en Tabla ---
Insert Into
Operaciones( Detalle)
Values ( 'Articulo 234-e
venta')
--- Obtención
del @Id ---
Declare @Id integer
Select @Id = @@identity
-- Si todo ok
Commiteo Transacción/else Rollback --
If @@ERROR = 0
Commit Transaction
Else
Rollback Transaction
Pero está la solución
de incluir en una transacción el proceso de insertado en la tabla cuore es una
alternativa exenta de eventuales inconvenientes?
Pues no … veamos dos
posibles consecuencias adicionales:
Ø Huecos en la Correlatividad de IDs
En caso de ROLLBACK, el id correspondiente a la transacción “rolbackeada”
se perderá, generando un hueco en la
correlatividad de IDs que debemos solucionar con un costo adicional asociado a
ello…
Ø Problemas de Contención
Adicionalmente y
volviendo a las horas pico donde varios hilos intentan insertar registros en
nuestra tabla de Operaciones, encontraremos que dichos hilos se serializan
esperando por el cierre de transacción precedente. Por lo tanto, los lockeos se
prolongan más de lo tolerable, pudiendo
producirse bloqueos y hasta deadlocks….
Utilidad
Diría que este método
es el más útil y sencillo de implementar en escenarios donde la concurrencia es
escasa a moderada y los volúmenes de la tablas no son tan importantes. Siempre
teniendo en cuenta las precauciones que hemos descripto a la largo de la
explicación del mismo.
METODO 2. Generación de ID por Cálculo
Se trata de una solución
que no recomiendo en absoluto pero que he visto en muchos sistemas aún
productivos.
El método consiste en tomar el máximo ID de la tabla y
sumarle un dígito… para así generar el ID para el nuevo registro.
Ejemplo:
-- 1) Creación Tabla --
CREATE TABLE
Operaciones
(Id int NOT NULL,
Detalle varchar(50) NULL)
-- 2) Seteo
de la Pk al campo "Id" --
ALTER TABLE [dbo].[Operaciones]
ADD CONSTRAINT [PK_Operaciones] PRIMARY KEY CLUSTERED
([Id] ASC)
GO
-- 3) Cálculo
del @id e Inserción en Tabla --
Begin Transaction
Declare @Id integer
--- Obtención de id por cálculo --
Select @Id =
coalesce (max(id),0) + 1 from
Operaciones
--- Inserción de registro en Tabla ---
Insert into
Operaciones(id, Detalle)
values (@Id, 'Articulo 234-e venta')
Ventajas
No encuentro ventaja
alguna más allá de cierta facilidad en
el grado de implementación y comprensión de la rutina en programadores menos
experimentados.
Desventajas
Ø Alto grado de contención / Bloqueos / Deadlocks
En términos de
performance esta elección es por lejos la peor debido a la baja performance que
resulta de la utilización constante de la función MAX().
A esto se le debe sumar
que la contención complementaria por estar esta solución embebida en una
transacción en lo referente a la obtención del id y su inserción.
Utilidad
---
METODO 3. Generación de ID mediante un GUID (Global Unique Id)
Ante todo recordemos que un GUID es un tipo de datos binario de 16 bytes
globalmente único en tablas, bases de datos y servidores.
EL método consiste en generar el ID de tipo uniqueidentifier e insertarlo
como nuevo Id de la tabla.
Ejemplo:
-- 1) Creación de Tabla --
Create Table Operaciones
(Id uniqueidentifier NOT NULL,
Detalle varchar(50) NULL)
-- 2) Obtención
@Id por medio de función --
Declare @Id uniqueidentifier
Select @id =
NEWID()
-- 3)
Inserción del registro en la tabla --
Insert into
Operaciones(id, Detalle)
values (@id, 'Articulo 234-e venta')
(*) Existe una opción de generar el id utilizando como valor por default
el NEWID() o NEWSEQUENTIALID() , pero no
es considerada en este contexto en el cual debemos recuperar el id recién
insertado para poder seguir insertando el mismo en otras tablas.
Ventajas
Se trata de un método que nos
garantiza la unicidad del ID generado para todos los objetos de nuestra base de
datos.
Al ser el @Id único, no hace falta embeber el proceso de inserción dentro
de una transacción evitando desde ese lado contención.
Desventajas
Ø Tipo de Datos poco performante y no apto para ciertas
lógicas de negocio
El tipo de datos uniqueidentifier con sus 16 bytes definitivamente es un
problema de performance en puerta para la buena performance de un sistema
fuertemente transaccional.
Por las características típicas de este tipo de datos es poco amigable
con la mayoría de las lógicas de negocio, al menos con las que uno está
acostumbrado a ver.
Al tratarse de datos “amplios” necesitaremos mayor almacenamiento y
mayores recursos. Recordemos también que cuando más “pesado” sea un registro menos
de este tipo de registros cabrán en memoria..con las consecuencias de
performance…
Utilidad
Es el único método que garantiza
unicidad de código en toda la base de datos.
METODO 4. Generación de ID “on the fly”
Se trata de un método similar al anterior en el cual se obtiene un ID que,
se pretende, sea único por su concepción. Se calcula a partir del uso de
funciones del sistema.
Se trabaja para ello con una variable de tipo Numeric amplia la cual permite jugar en este caso
hasta con los microsegundos de la fecha del sistema para evitar de ese modo
posibles duplicaciones.
Ejemplo:
-- 1) Creación Tabla --
Create Table Operaciones
(Id NUMERIC(19,0) NOT NULL,
Detalle varchar(50) NULL)
-- 2)
Seteo de la Pk al campo "Id"--
Alter Table [dbo].[Operaciones]
Add Constraint [PK_Operaciones] Primary Key Clustered
([Id] ASC)
GO
--3)
Obtención de @Id “On the Fly” -–
Declare @id numeric(19,0)
Select @id = (select cast((((datediff(SECOND,'1970-01-01', getdate())
+datepart(ms,getdate())/1000.0)*1000)+datepart(mcs,getdate())/1000.2)*1000
as numeric(16,0)))
-- 4)
Inserción del registro en la tabla --
Insert into
Operaciones(id, Detalle)
Values (@id, 'Articulo 234-e venta')
Ventajas
Es un método que obtiene muy buena performance en la obtención del ID y permite
asegurar la unicidad del mismo. Recordemos que al trabajar con precisión de
microsegundos es imposible que se repita el Id .
No hace falta embeber la inserción dentro de una transacción hecho que
permite asegurar la buena performance.
Desventajas
Ø Tipo de Datos poco performante y no apto para ciertas
lógicas de negocio
El tipo de datos tiene que tener una importante amplitud para poder
asegurar la unicidad creciendo en bytes…
La performance, si bien al trabajar con un dato de tipo numérico será
marcadamente mejor que la del caso anterior, no será igual de buena que
trabajando con tipo de datos más pequeños.
Adicionalmente la lógica de negocios tendría que permitirnos trabajar con
datos de esta amplitud.
Por último al igual que en el método anterior tendremos registros más
pesados y “grandes”, malgastando recursos y reduciendo el espacio disponible en
RAM.
Utilidad
Es un método válido para entornos con alta carga transaccional teniendo
en cuenta sus “desventajas”
METODO 5. Generación de ID en “Dummy Table”
Este método es a mi
juicio el más apto para soportar grandes cargas transaccionales con la mejor
performance y sin duplición IDs
Se crea para la obtención del ID una tabla “dummy”, la cual tendrá como
único objetivo el brindar el último ID secuencial.
Esta tabla permancerá siempre sin
registros. Simplemente se inserta un registro para “ mover” el identity ,
pasarlo a la variable @Id y borrarlo.
Ejemplo:
-- 1) Creación Tabla “Operaciones” --
Create Table
Operaciones
(Id int NOT NULL,
Detalle varchar(50) NULL)
-- 2)
Seteo de la Pk al campo "Id" --
Alter Table [dbo].[Operaciones]
Add Constraint [PK_Operaciones] Primary Key Clustered
([Id] ASC)
GO
-- 3)
Creación de la "Dummy Table" --
CREATE TABLE
Operaciones_kEYTABLE
(Id int NOT NULL IDENTITY(1, 1))
-- 4)
Obtención del ID desde la tabla "Dummy Table" --
Declare @Id int
Begin Transaction
Insert Operaciones_kEYTABLE DEFAULT VALUES;
Select @Id = SCOPE_IDENTITY();
Delete From Operaciones_kEYTABLE
Commit Transaction
-- 5)
Inserción de un registro nuevo en la tabla “Operaciones”--
Insert into
Operaciones(id, Detalle)
Values
(@id, 'Articulo
234-e venta')
Ventajas
Se trata de un método que nos
garantiza la unicidad del ID generado y la mejor performance en el proceso de
inserción de la tabla “cuore”.
Al estar embebido en la transacción sólo la obtención del id en la tabla
dummy no tiene casi contención.
Al ser la tabla dummy una tabla sin registros la velocidad de obención
del Id es la mejor de todos los métodos tratados en este artículo.
Desventajas
--
Utilidad
Es el métedo más apropiado para su implementación en ambientes como el
descripto al comienzo de este post.
METODO 6. Generación de ID por medio de Sequence Object
Se trata de un método válido cuando se necesite mantener la secuencialidad de los valores de un id en forma estricta acorde a reglas de negocio.
Se obtiene un valor para una columna Id a partir un objeto introducido en Sql Server 2012 que permite gestionar el mismo. Con alguna similaridad con la columna "identity" se diferencia de la misma en que el objeto identity no está "atado" a una tabla y por lo tanto tiene sus ventajas y desventajas que luego detallaremos.
No está dentro del scope de este artículo el explicar paso a paso su sintaxys sin embargo veremos un ejemplo extraído de la página https://www.sqlshack.com/sequence-objects-in-sql-server/ - página de un querido colega que desde ya recomiendo -.
Manos a la obra, lo primero que debemos hacer es crear un objeto sequence al que llamaremos "IdCounter", dentro de la base de datos en la que precisemos de id único y secuencial:
Use Padron
CREATE SEQUENCE [dbo].[IdCounter]
AS INT
START WITH 1
INCREMENT BY 1
Ahora procedereos a insertar registros en la tabla Students utilizando el Id provisto por el objeto creado en el paso anterior de la siguiente forma:
| NEXT VALUE FOR [dbo].[IdCounter] |
USE School
INSERT INTO Students VALUES (NEXT VALUE FOR [dbo].[IdCounter], 'Sally', 20 )
INSERT INTO Students VALUES (NEXT VALUE FOR [dbo].[IdCounter],'Edward', 36 )
INSERT INTO Students VALUES (NEXT VALUE FOR [dbo].[IdCounter],'Jon', 35)
INSERT INTO Students VALUES (NEXT VALUE FOR [dbo].[IdCounter],'Scot', 41 )
INSERT INTO Students VALUES (NEXT VALUE FOR [dbo].[IdCounter],'Ben', 35 )
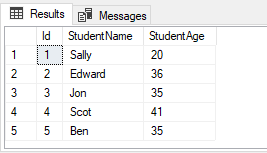
Luego haremos un select de la tabla y veremos como se han insertado correctamente los ids ssecuenciales generados a partir del objeto "IdCounter"
SELECT * FROM Students
Ventajas
Es un método que BIEN IMPLEMENTADO garantiza la secuencialidad de un Id , algo imposible de ser garantizado con un campo identity.
Desventajas
- Al ser el valor de un sequence updeteable, es una enorme tentación de hacerlo para alguien que tienen los privilegios dentro de la base. Luego vienen los reclamos del tipo"no se qué pasó se perdió la correlatividad"...
- Ante casos de apagados repentinos del motor, y dado que la mayoría suele hacer uso del sequence cacheado, el mismo se pierde. Se vacía el caché y se pierde..
- El sequence, al igual que el identity, no es garantía de unicidad. Por definición no
garantiza la misma y me ha ocurrido de ver duplicaciones en procesos cíclicos de obtención de id secuencial o en updates complejos.
- No se suele usar con criterio el valor default del sequence. Cuando tu vas revisar te sueles encontrar con valores por defecto definidos como integer o biginteger cuando en verdad con un small integer hubiera sido suficiente . Esto trae problemas de peformance y espacio mal utilizado.
Utilidad
Si lo utilizamos con criterio, es decir evitando las malas prácticas que devienen en sus eventuales desventajas, es un excelente método a la hora de cumplir con estrictas reglas de negocio que exigen secuencialidad sin fisuras en el id de una tabla (ejemplo nº factura).
Amigos, es todo por ahora. Espero como siempre vuestras preguntas, apuntes y todo aquello que nos enriquezca.
Sigamos en contacto, saludos desde Argentina.







